Unsupervised Domain Adaptation for Personalized Action Recognition in Body Gesture Control for Mobile Robotics
Academics | | Links:
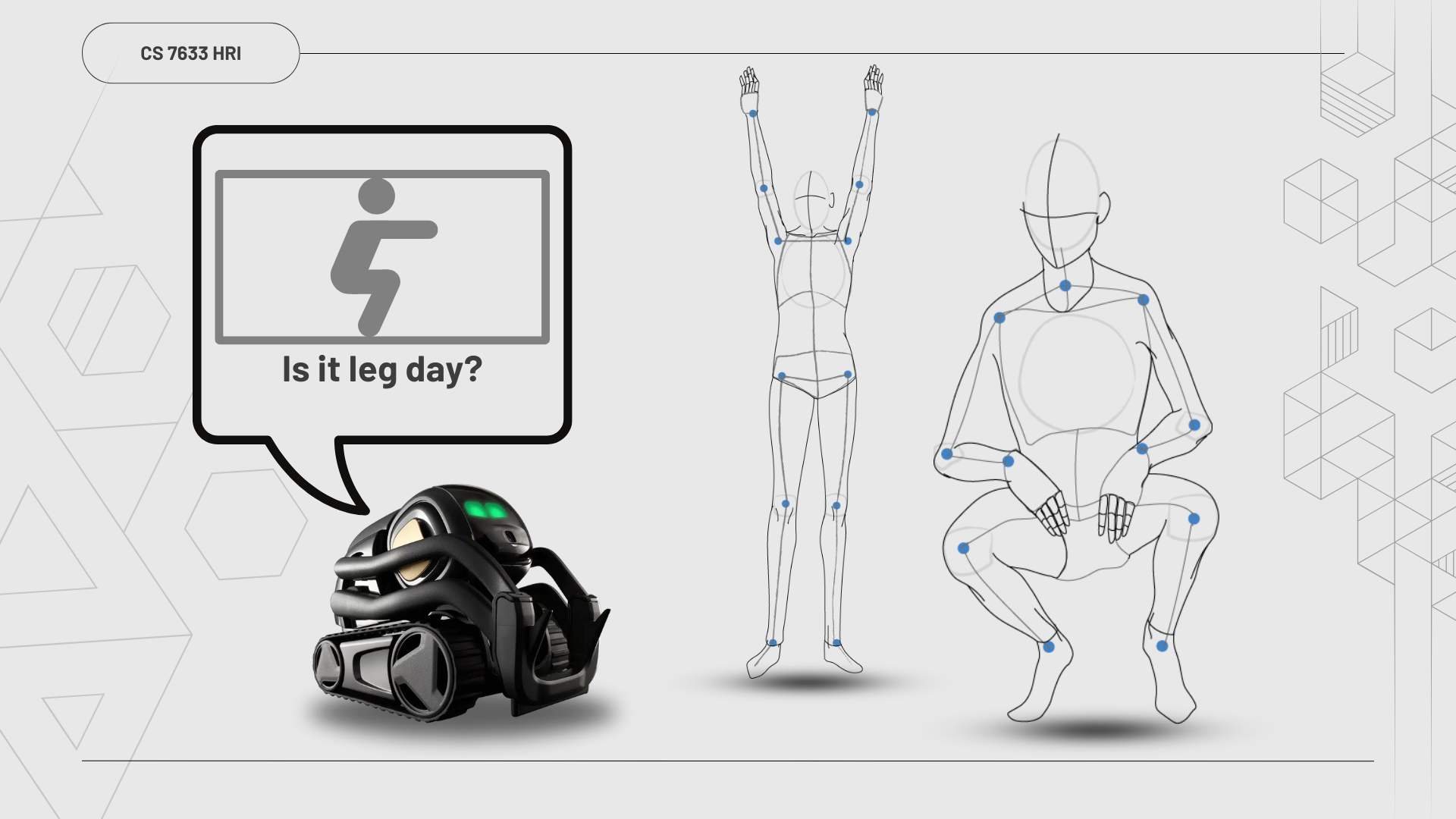
Robot gesture recognition (non-verbal gesture communication) research project centered on adapting perception domain to Anki Vector robot using Unsupervised Domain Adaption.
With a central focus of Human-Robot Interaction, this project aims to evaluate the impact of perspective domain shift in small mobile robots, using the Anki Vector and the MMPOSE/RTMO gesture recognition backbone. We generated Vector domain specific data in order to successfully implement Unsupervised Domain Adaptation (UDA) on RTMO and created unique gesture based responses on Vector. Our results explore the broader implications of robot perception domains and means of integration with modern computer vision.
Context & Motivations
Integrating the MMPose (RTMO) ML model and the Anki Vector Robot, we constructed a pose estimation pipeline for the Vector robot, having adapted the model’s domain to the small mobile robot’s perception domain using Unsupervised Domain Adaptation (UDA). The purpose of this project was to enable gesture recognition in the Vector robot for the purposes of human gesture based non-verbal communication and interaction. We sought to address the following challenges:
- Perspective shift
- Lack of data from Vector robot perspective
- Customizable actions
- Improve gesture perception generalizability
- Data generation with low resource needs
- Customizable gestures commands
- Command registering using keypoint features

Vector robot perspective domain
Relevant Works
The RTMO backbone leveraging the MMPOSE toolkit served as a fundamental starting point for this project [2-3]. RTMO builds on the RTMPose architecture and is state of the art in terms of general body pose recognition. We referenced [4] and [1] to develop a deeper understanding of the domain shifts and [5] in terms of developing domain specific gesture data.
Methodology
We devised a collection of 7 gesture classifications, which we then recorded using the Vector robot. Since Anki is no longer in operation, we relied on user created tools such as the Vector Wirepod for establishing wireless communication with Vector and the unofficial Python SDK to gain access to Vector’s features and controls. I automated temporal data collection on Vector using custom image capturing at 8 fps.
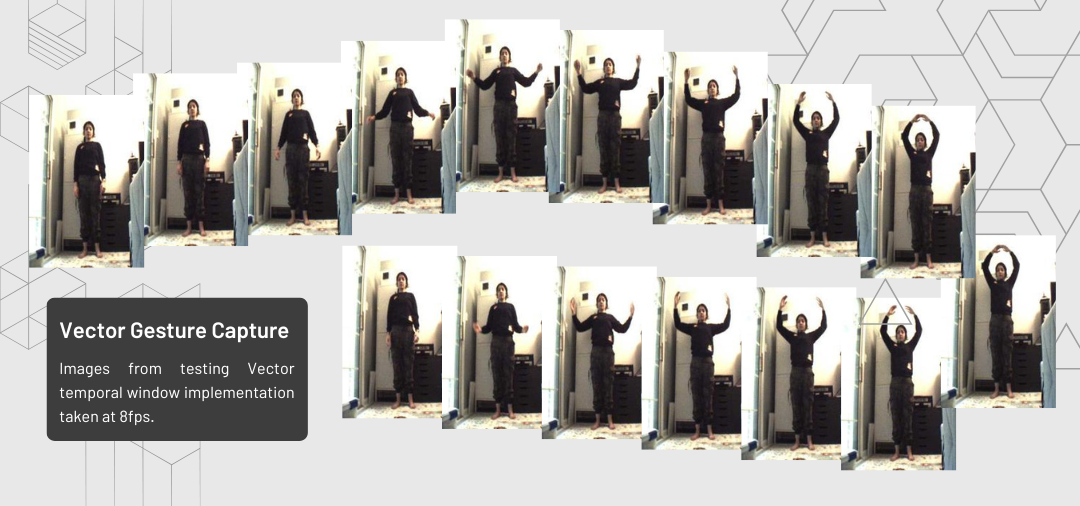
Vector perspective domain data generation
Gesture Class with Vector Responses
We recorded the following gesture data classifications for the UDA implementation:
- Both Hands Raised
- Squat
- Crossing Arms (No)
- Circle Above Head (Yes)
- 1 Hand Raised
- Legs in Superhero Pose (A-Frame)
- Wave Single Hand (Goodbye)
With the RTMO model adapted to our gesture classifications, I then developed custom responses on Vector using the Vector Python SDK. Vector would exhibit a unique combination of physical movements, utterances, and graphic display on his screen for each classification.
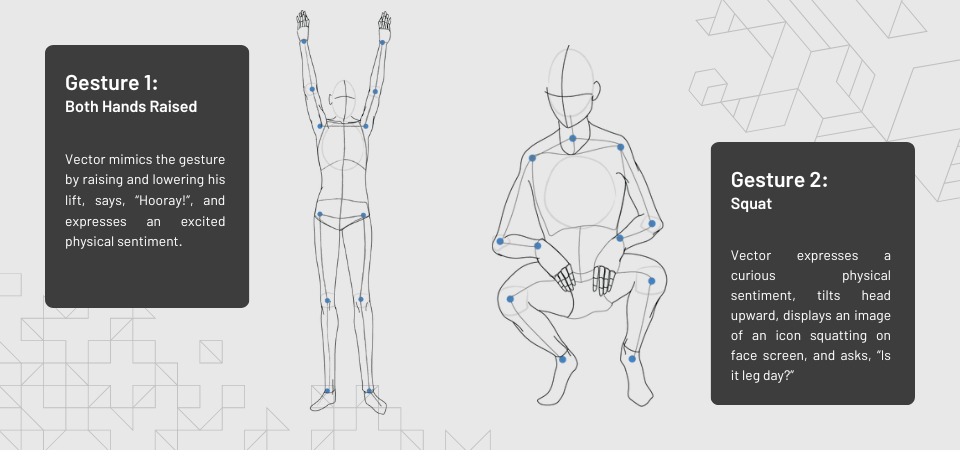
Vector gesture responses with gesture diagrams
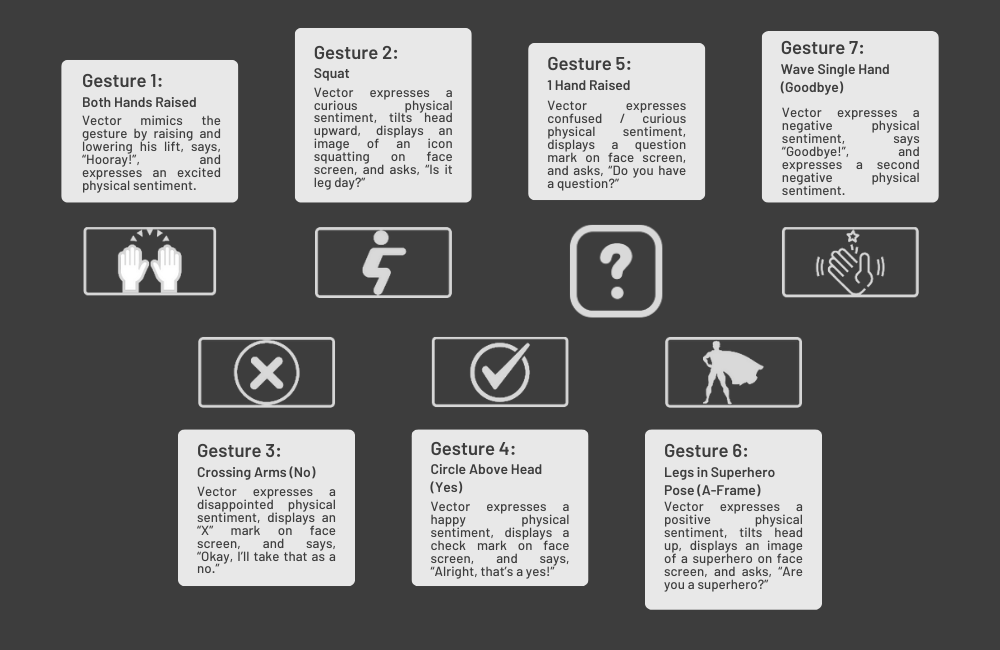
Vector behavioral responses and display screen graphic projections to gesture classifications
RTMO Backbone + Perspective Aware Classification
The RTMO model that served as our backbone came pretrained on generalized gesture data using keypoint features and had extensive recognition capabilities. It is capable of gesture recognition in crowds and occluded image gesture recognition. An adversarial domain discriminator was incorporated with the classifier to impelement the UDA.
Results
We saw significant improvement with Vector’s perspective domain gesture recognition from the UDA impelementation. Using a mix of Vector captured data and fixed laptop camera data, we achieved a 99.3% accuracy.
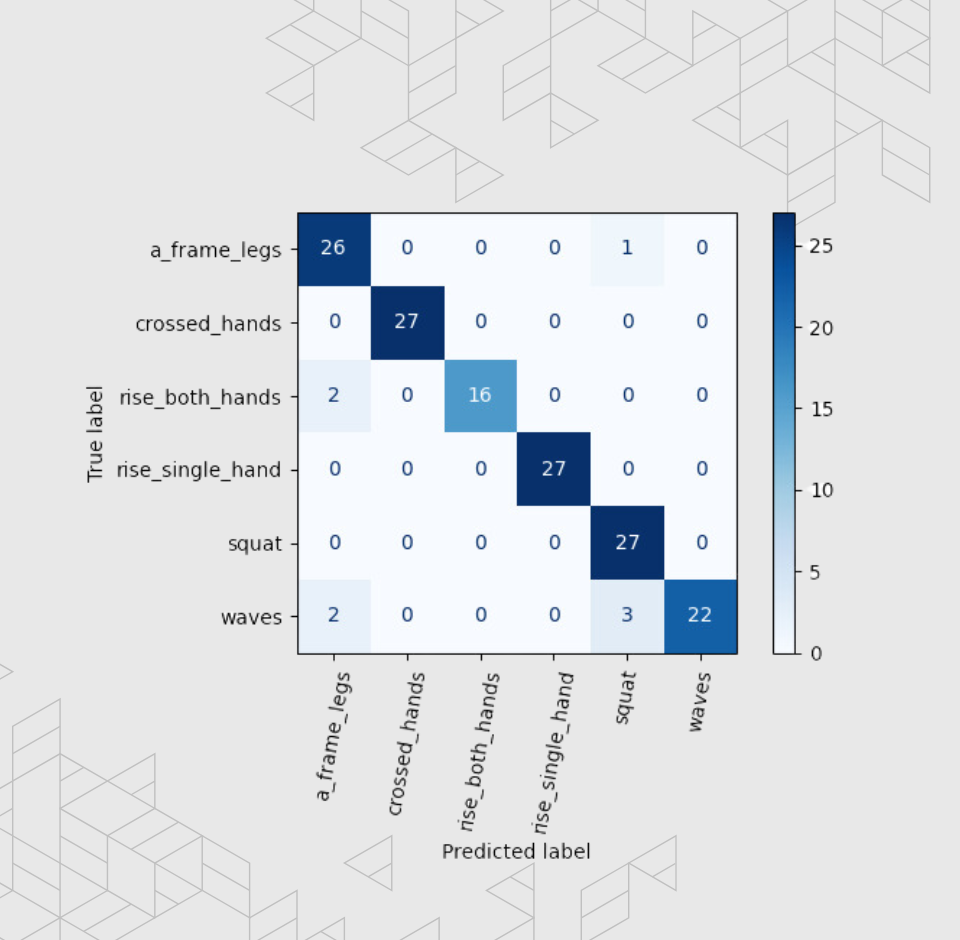
Confusion matrix for mixed dataset
With just Vector generated data, we achieved a precision of 0.862 and F1 score of 0.851.
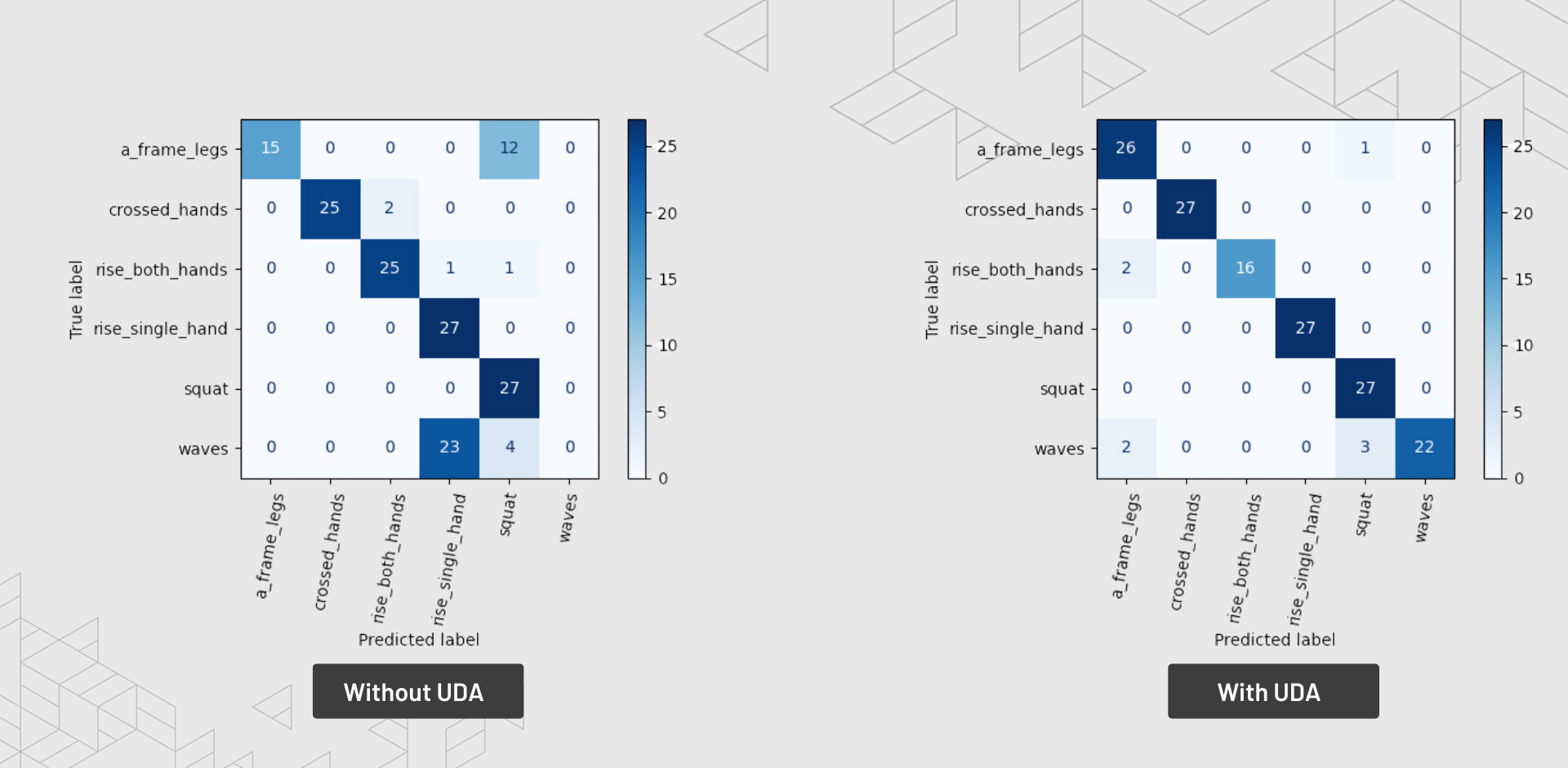
Comparison of confusion matrices for action classification on robot perspective dataset
Limitations & Conclusions
An area that has yet to be explored in this project is extending the dataset to multiple users in order to broaden the generalizability of the model. With the dataset’s limited size, recognition capabilities in various environments has yet to be tested. While the RTMO model has been trained for gesture recognition inclusive of occluded figures, the new classifications have yet to be validated with occlusions as well. Even so within the scope of this project, we successfully achieved model domain adaptation to the Vector robot domain perspective.
Key References
- D. Kim, K. Wang, K. Saenko, M. Betke, and S. Sclaroff, “A unified framework for domain adaptive pose estimation,” arXiv preprint arXiv:2204.00172, 2022. 1
- T. Jiang, P. Lu, L. Zhang, N. Ma, R. Han, C. Lyu, Y. Li, and K. Chen,“Rtmpose: Real-time multi-person pose estimation based on mmpose,” arXiv preprint arXiv:2303.07399, 2023.2
- T. Jiang, X. Xie, and Y. Li, “Rtmw: Real-time multi-person 2d and 3d whole-body pose estimation,” arXiv preprint arXiv:2407.08634, 2024.3
- K. Zhang, B. Scholkopf, K. Muandet, and Z. Wang, “Domain adaptation under target and conditional shift,” in International Conference on Machine Learning, 2013, pp. 819–827. 4
- A. Kollakidou, F. Haarslev, C. Odabasi, L. Bodenhagen, and N. Kr¨uger,“Hri-gestures: Gesture recognition for human-robot interaction,” in Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2022) - Volume 5: VISAPP, 2022, pp. 559–566. 5
