Knowledge Distillation for TinyML/Embedded AI: Model Distillation with Time Series Data
Academics | | Links:
We sought to analyze the impact of time series data in the model distillation pipeline. Using Wav2Vec2-base as the teacher model (95M parameters) and the TESS dataset, we distilled learning to two student models, Wav2Small (90K parameters) and our Wav2Tiny (15K parameters).
TinyML is an emerging field for on device machine learning. Using knowledge distillation from a Wav2Vec2-base[1] teacher model and two student models of varied reduced sizes, we focused on the impact of time series data in the distillation pipeline. We finetuned Wav2Vec2-base (95M parameters) using the Speech Emotion Recognition (SER) dataset TESS to a 98.3% accuracy. Knowledge from this teacher model was distilled to Wav2Small (90K parameters) at a 94.8% accuracy and our Wav2Tiny (15K parameters) at a 86.3% accuracy.

SER Models
Research Problem
Machine Learning has enabled an unprecedented level of device intelligence in recent years and with the various model types available, that intelligence can be tailored to a variety of tasks and insights. Our interest lay in the exploration of deploying machine learning models directly onto small scale devices themselves. Due to the often heavy computational costs involved, we investigated TinyML techniques geared towards model scale reduction while maintaining performance accuracy with a focus on time series data. Time series data in the context of Speech Emotion Recognition (SER) presents a unique challenge as a classification task, as it necessitates the categorization of potentially subjective classifications over continuously distributed data.
Setting & Key Related Works
Teacher Model: Wav2Vec2
As mentioned, we used Wav2Vec2-base as our teacher model, a transformer model capable of a variety of tasks using raw audio data sampled at 16kHz. The base version had been trained on a large generalized audio dataset, which we then finetuned for the SER task. The model is capable of achieving high classification accuracy with limited avialable data, with reported results demonstrating this capacity with as little as one hour of audio data.[1]
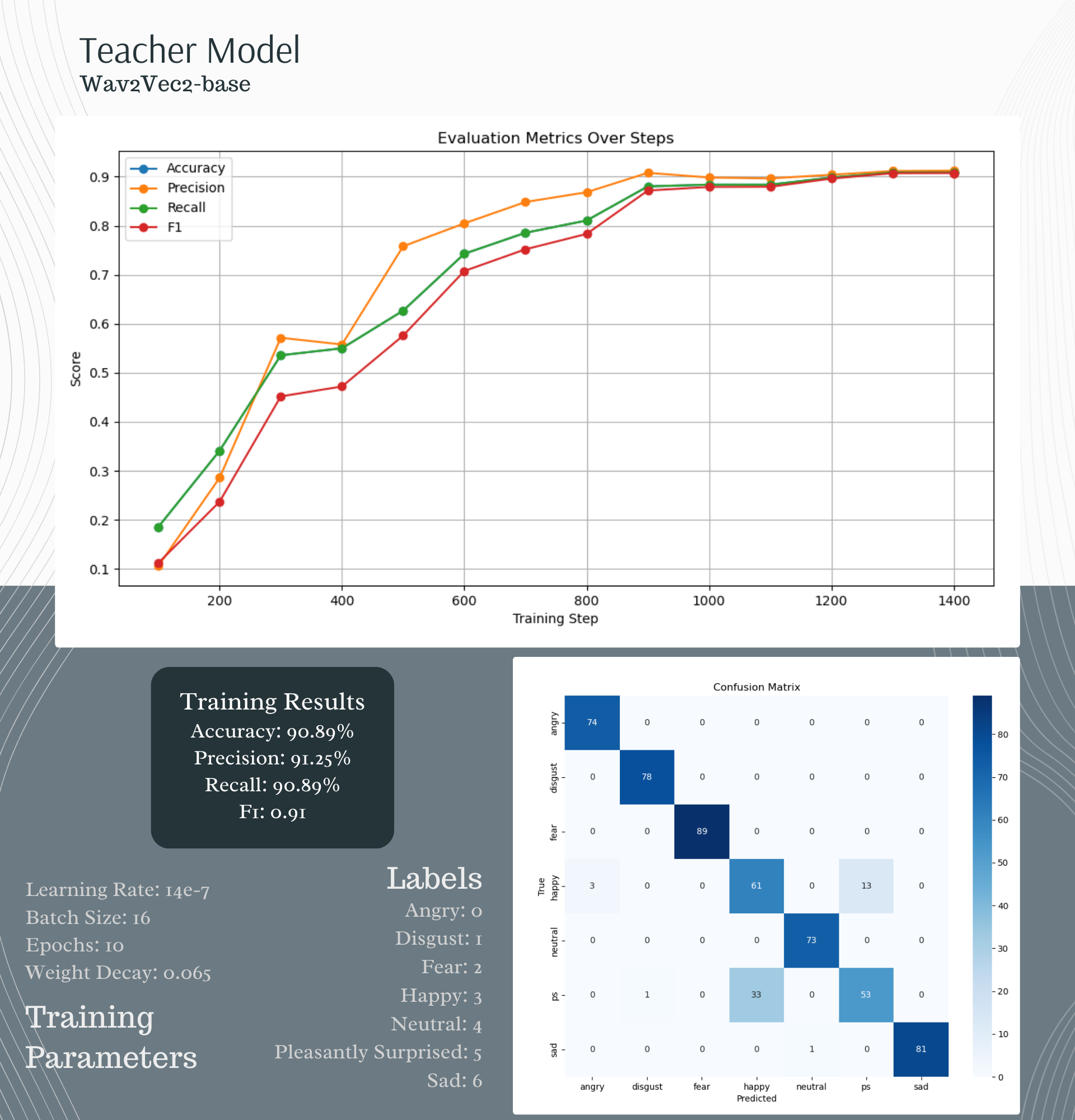
Wav2Vec2 Teacher Model training results and hyperparameters
Student Model 1: Wav2Small[2]
A key reference for our project was the research done by the audEERING group on knowledge distillation and their development of the Wav2Small model architecture, which consists of a VGG7-based convolutional encoder with input normalization, LogMel filter bank generation, pooling layers, and a global mean pooling layer. We adapted this model with a linear classification head. The spectrogram layer converts the raw audio into a time-frequency represenatation by applying the Short-Time Fourier Transfomr (STFT), which is then converted into a log-mel spectrogram. The log-mel spectrogram is then passed through the vgg7 block for feature extraction.

Wav2Small Student Model architecture and hyperparameters
Student Model 2: Wav2Tiny
Leveraging the insights provided in [2] on the advantages of the vgg7 approach to audio feature extraction combined with the simplified classification task, we further experimented with our own variation of a reduced model size, which we dubbed Wav2Tiny. This second student model resulted in around 15K parameters.
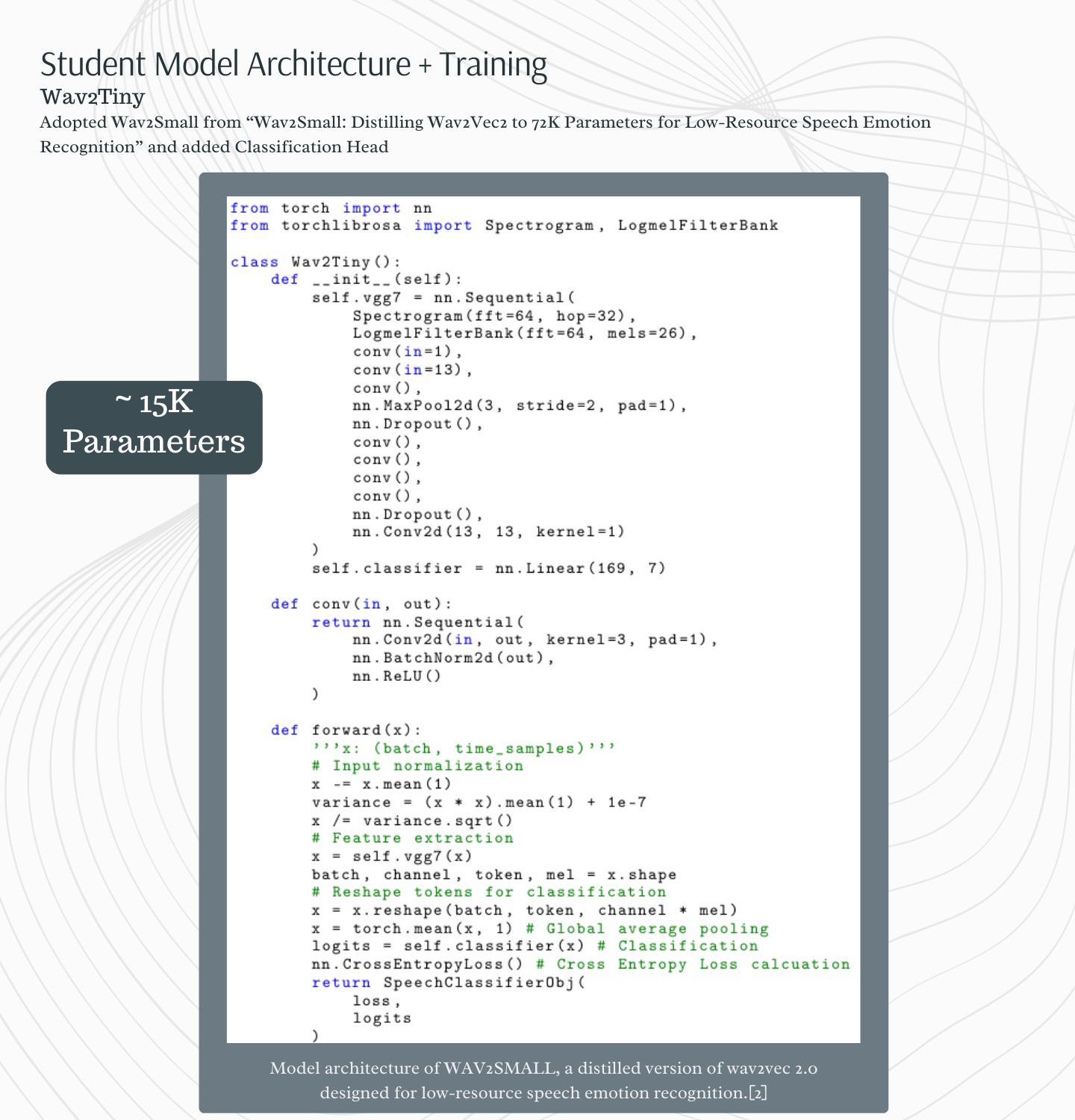
Wav2Tiny Student Model architecture
Dataset: TESS
The TESS dataset was used to finetune the Wav2Vec2 teacher model for the SER classfication task. It consists of seven emotion classifications: anger, disgust, fear, happiness, pleasant surprise, sadness, and neutral and with 2800 total datapoints, was split with 2240 samples for training and 560 samples for testing. The samples themselves are high quality audio recordings in a .wav format.
Core Works Referenced
Since this was an introductory TinyML project, we sourced informative learning references for foundational theory, as well as broad ranging TinyML papers surveying applications[5] in order to gain a better understanding of the core principles and current status of the topics. Hinton, et al’s seminal work on knowledge distillation, “Distilling the Knowledge in a Neural Network”(2015) [4] is often cited as a core methodology establishing piece, demonstrating the effectiveness of the teacher/student learning paradigm. As mentioned in other sections [2] also served as a main reference for our student models and their architecture design for lightweight handling of time series data.
Methodology
The main distillation pipeline was constructed using the finetuned teacher model, a trainer class, the two interchangeable student models, and the TESS Dataset.
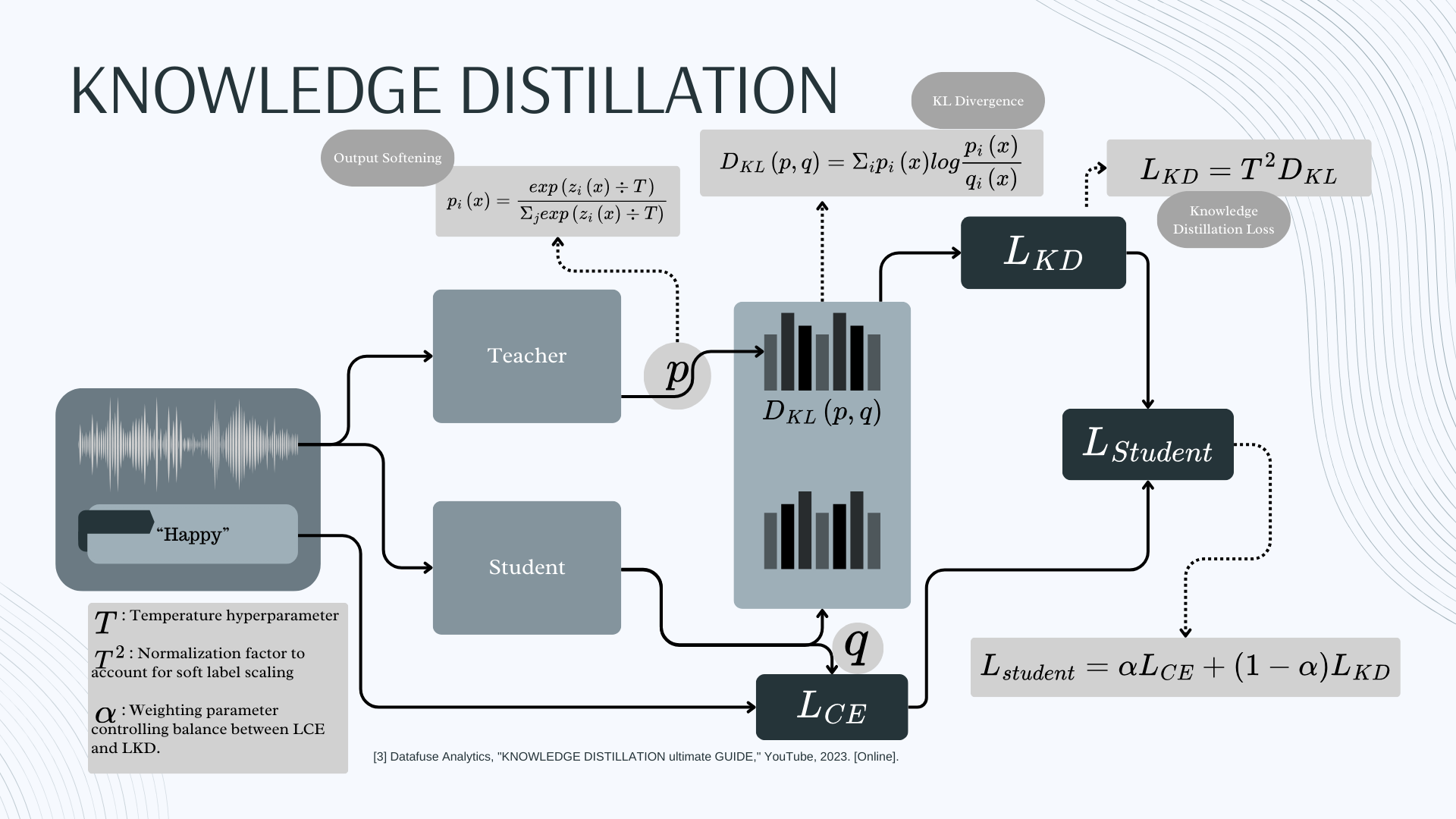
Knowledge Distillation Pipeline
The predictions of the teacher model are softened using a temperature parameter (T), which adjusts the logits to better capture the subtle relationships between class prediction output.

Teacher Model prediction softening
The softened output loss calculation is done using KL Divergence times a normalizing square of the Temperature parameter:

Softened Teacher Loss
The student model is simultaneously calculating its own Cross Entropy Loss and the final loss for learning is a combination of the teacher model’s loss and the student model’s loss, with each loss’s contributing weight being dictated by the α parameter:
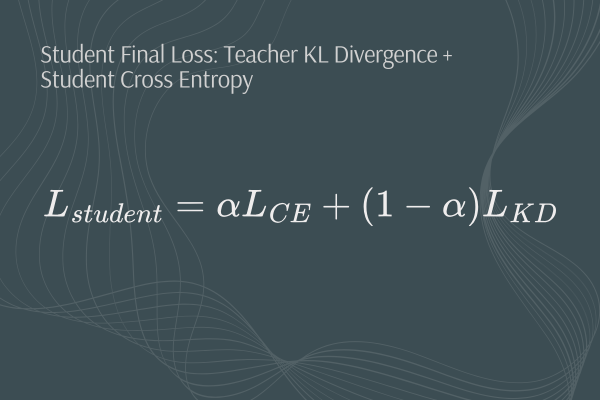
Final Student Loss
In summary there are two variables impacting the distillation process: the temperature and α parameters.
Experiments & Results
With each student model, Wav2Small and Wav2Tiny, we analyzed the impact both new hyperparameters, temperature and α, have on the learning process. We conducted three experiments per temperature setting; for each temperature setting, 1.0, 2.0, and 3.0, we tested α values 0.0, 0.5, and 1.0.
Comparison of Wav2Vec2-base with Wav2Small and Wav2Tiny performance metrics with α set to 0.5 and T set to 2.0.
The α hyperparameter was evaluated using an an ablation study:
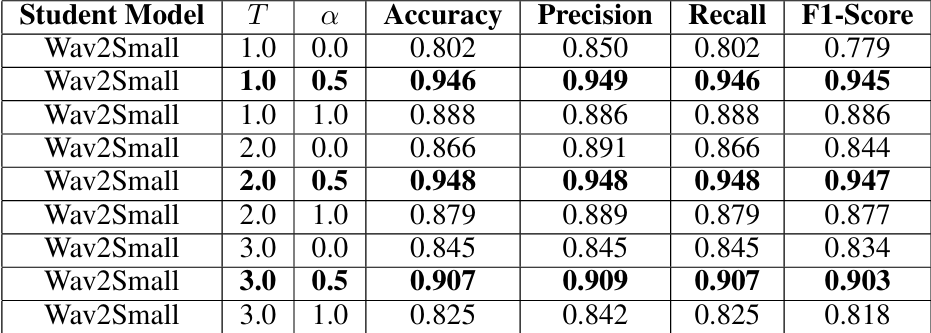
Performance metrics for Wav2Small
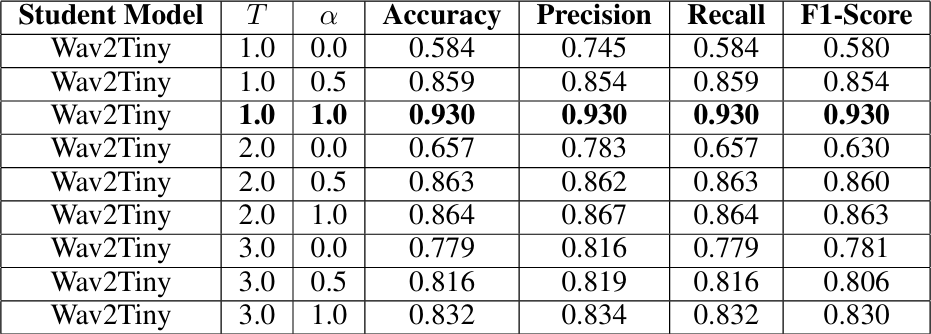
Performance metrics for Wav2Tiny
Wav2Small consistently performed the best at α set to 0.5 for all three temperature values, achieving accuracies above 90%. Wav2Tiny surprisingly performed best without the teacher model’s input (α set to 1.0), achieving an accuracy of 93%.
Wav2Small experienced confusion between the categories angry, disgust, happy and pleasantly surprised:
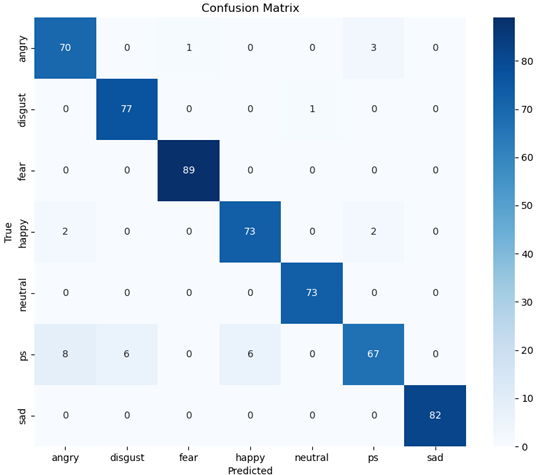
Wav2Small confusion matrix (T = 2, α = 0.5)
Wav2Tiny experienced confusion between pleasantly surprised, happy, disgust, angry, and fear the most:
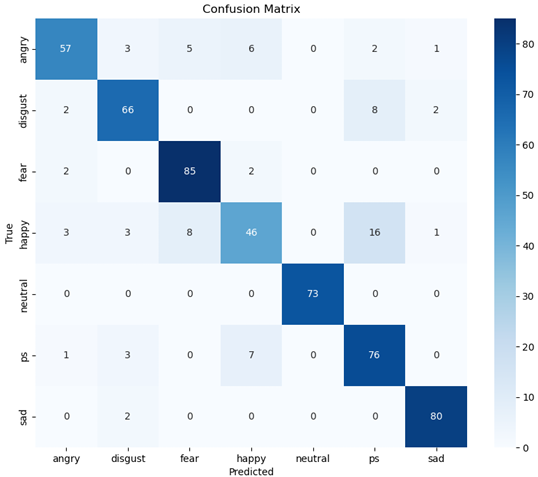
Wav2Tiny confusion matrix (T = 2, α = 0.5)
Discussion & Insights Gained
It bears noting that when α is 1.0, the student model is learning entirely independently of the teacher’s input. In this sense, Wav2Tiny performed better without the teacher model’s input. This may be due to the extreme size difference between the teacher model and Wav2Tiny, going from 95M parameters to 15K may have been too large of a gap. Investigating the cause of this requires further research exploration.
Both student models experienced more confusion between emotion categories than the teacher model. Further exploration is needed on this as well, but it is important to consider the visual similarities and differences in the spectrograms as that is the source for feature extraction:
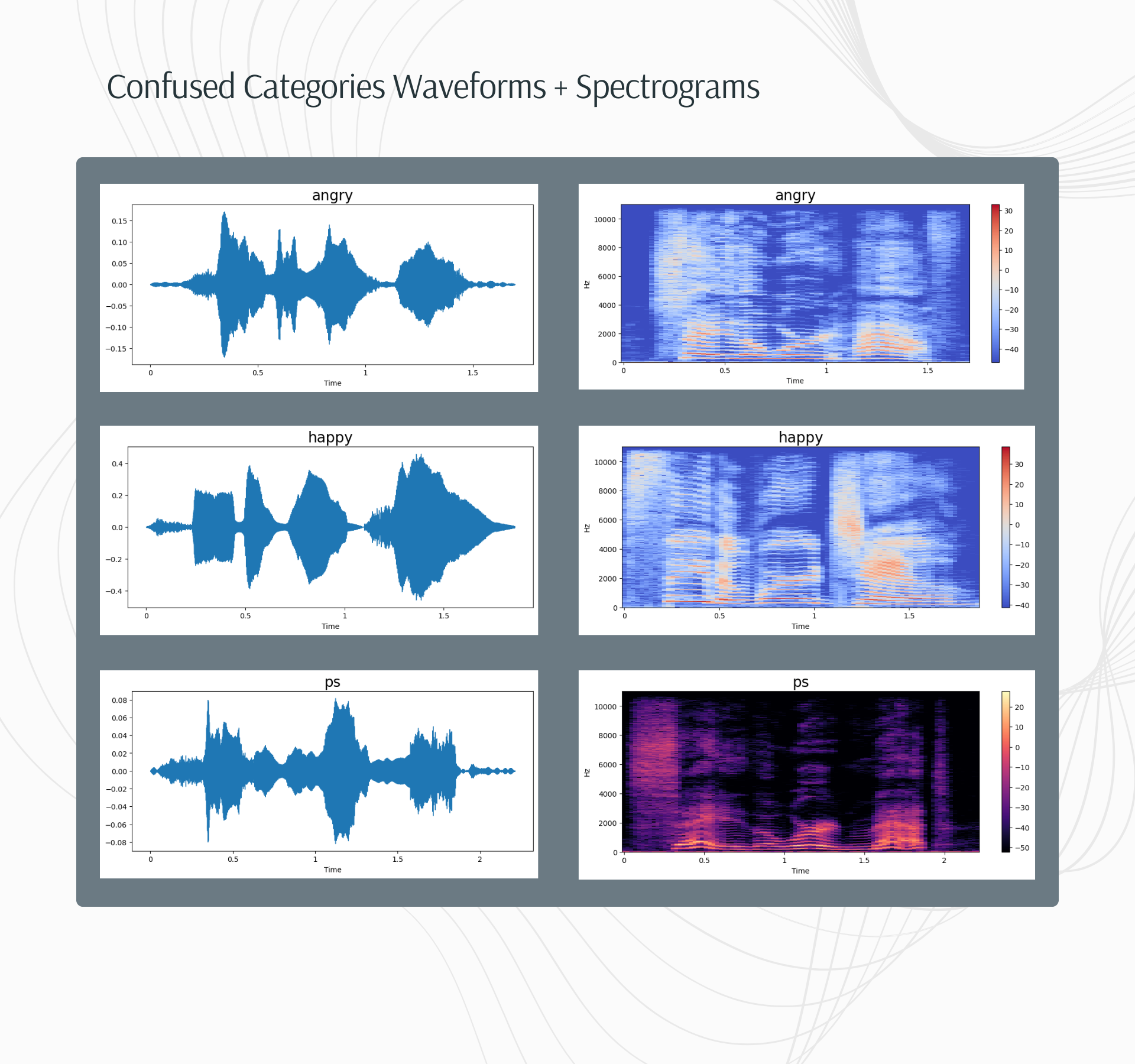
Category waveforms and spectrograms
Conclusion
We were able to distinguish the impact of the teacher prediction softening and the teacher loss inclusion/exclusion to varying degrees. Wav2Small demonstrated a postive impact from teacher guided learning with 94.82% accuracy, while Wav2Tiny requires further study as to the lack of teacher based improvement, but still demonstrated accuracy results of 93% at a significantly reduced model size. I will be further extending this study to examine the impact of optimal experimental design on the learning process in the subsequent semester.
Key References
A. Baevski, H. Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self supervised learning of speech representations,” in Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020), Vancouver, Canada, 2020. 1
D. Kounades-Bastian, O. Schrüfer, A. Derington, H. Wierstorf, F. Eyben, F. Burkhardt, and B. W. Schuller, “WAV2SMALL: Distilling Wav2Vec2 to 72K Parameters for Low-Resource Speech Emotion Recognition,” arXiv preprint arXiv:2408.13920, 2024. 2
Datafuse Analytics, “KNOWLEDGE DISTILLATION ultimate GUIDE,” YouTube, 2023.3
Hinton, G., Vinyals, O., & Dean, J., “Distilling the Knowledge in a Neural Network,” arXiv preprint arXiv:1503.02531, 2015. 4
Gou, J., Yu, B., Maybank, S. J., & Tao, D., “Knowledge Distillation: A Survey,” arXiv preprint arXiv:2006.05525, 2021.5
